Contextual metadata and the dangers of standardization
In the ongoing paradigm-shift from knowledge push to knowledge pull (Naeve, 2005), an increasingly valuable type of contextual metadata on a resource is comments from users about what they thought of its value in various contexts – especially if this metadata can be made searchable and retrievable.
In 1988, when refusing to accept the Swedish Crawford medal, the French mathematician Alexandre Groethendick stated that “let my work be judged by its offspring and not by its offering.” This way of thinking about publication represents a paradigm shift away from the traditional closed publication systems towards towards open publications that offer searchable semantic links for comments (annotations).
Semantic Web techniques make it possible for a resource to have distributed metadata that can be aggregated and processed independently of where it is stored on the web. This type of resource-centric and contextualized metadata is the basis for the annotation techniques and tools that have been developed by the KMR group. See e.g., (Palmér et al, 2004).
The Change-By-Increment Design Principle
Such techniques and tools operate according to the change-by-increment design principle that is enabled by a graph-centric view of looking at metadata (compare the figure below). For example, the reputation of a publication can be changed by somebody pointing to it and expressing her/his opinions about it. If this person has a high standing in the community and expresses the opinion that the publication represents a valuable contribution, then this publication will increase in importance (Korfiatis and Naeve, 2005). This is an important aspect of what is sometimes referred to as “the web of trust.”
Incrementally updating a description from black (= first) to blue (= second) to red (= third):
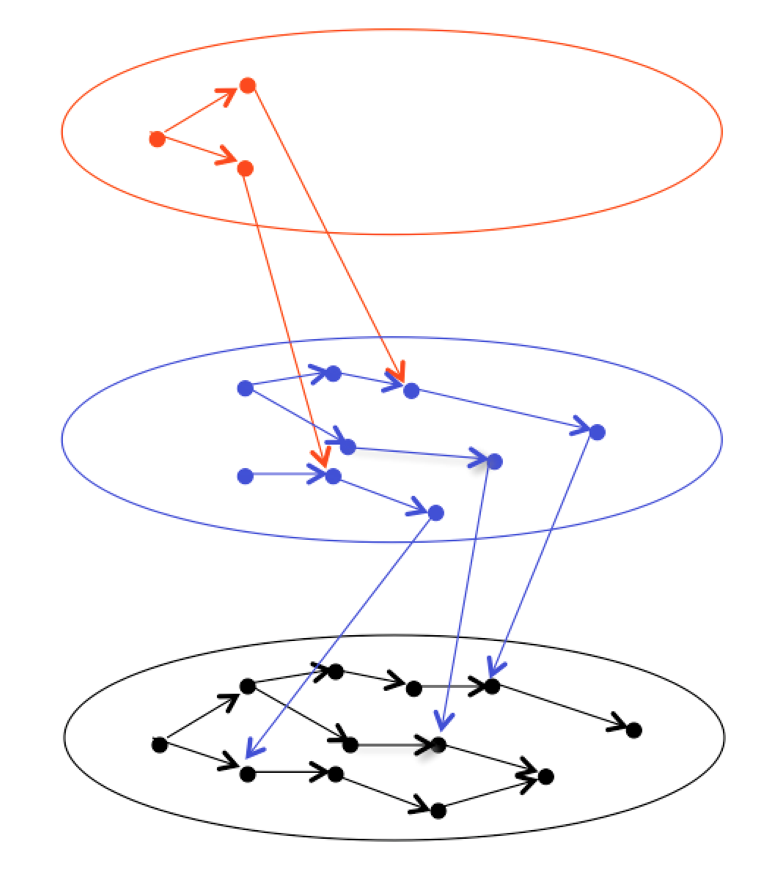
Applying the change-by-increment pattern to an evolving discourse
In this type of environment, associating metadata with a resource becomes a never-ending annotation process, which creates a kind of metadata ecosystem (Nilsson et al, 2002), where the user feedback provides a selection pressure that supports the evolution of quality by highlighting resources of high quality. In this metadata ecosystem, every community of practice has its own specific description needs that should be possible to add on top of various standards.
Therefore, what is needed is an open-ended description system that allows for new elements to be added without changing the old descriptions – but rather reusing the parts of the old descriptions that are still valid. In this way it becomes possible to apply the change by increment principle that has made object-oriented programming such an immense success.
The technical infrastructure of the Semantic Web – RDF(S) – provides the basis for such a system. Just like an ordinary language, RDF(S) provides rules for HOW to express information, while leaving the user free to choose WHAT to express. Unfortunately, most of the present metadata standards have focused on WHAT to express, which has lead to increasing problems of interoperability.
Supporting and enhancing opportunistic collaboration
Semantic Web technologies enable a shift away from the traditional closed, document-centric, and text-based annotation techniques, and towards open, graph-centric, and unique-address-based approaches to handling discourses, i.e., recording, storing, annotating, and retrieving them.
This represents a real paradigm shift since it enables three important improvements: (i) an open descriptional system which allows unknown descriptional elements (tags), (ii) global distribution of metadata (annotations) about a resource, and (iii) a change-by-increment approach to resource descriptions. Taken together, these improvements increase the possibilities for opportunistic collaboration by making it easier to handle the description of evolving and interlinking web-based interactions.
(i) The underlying descriptive technology RDF(S) provides an open descriptional system, where an unexpected description tag, which is found at runtime does not crash the system. This is in contrast to the traditional, document-centric descriptive approaches, which lead to closed descriptional systems, where all allowed description tags must be declared at compile time.
(ii): The information about the information (metadata) can be as distributed as the information itself without losing track of what the information is referring to. This is because the metadata system allows the unique identification of the concepts and resources that are being described, as well as the description tags that are being used. Because of the unique identity (URI) of everything that is being described, on the Semantic Web anyone can state anything about anything in a way that is retrievable by machines.
This allows our descriptional systems to be transformed from the traditional centralized opinion registration systems to distributed opinion publication systems. Hence the Semantic Web can support the assessment of a piece of information a posteriori (= by its offspring) instead of a priori (= by its offering).
(iii): Since the metadata is structured in the form of a graph (as when expressed e.g., in RDF) and not in the form of a collection of documents (as when expressed e.g., in XML), updating the descriptions can be performed in the way shown in Figure 221 i.e., by adding new nodes to the graph and pointing into the old parts (sub-graphs), which are still valid. This makes updating the information a lot easier and creates a new type of window of opportunity for opportunistic collaboration, by lowering the thresholds of the difficulties involved.
In summary, the metadata ecology (Nilsson et al, 2002) can be seen as a descriptional aspect of the socio-cultural ecology (Pachler, 2009), which can keep track of evolving and interlinked discourses and promote the judgement of their value a posteriori (by their offspring).
This can be achieved because the metadata ecology has the following three important properties:
• It is semantically open-ended, i.e., it accepts unknown description tags without crashing.
• It supports unique identification of concepts (by the use of URIs for both described and describing entities.
• It allows incremental updating (= change by increment) of all descriptions.
////////